1. Metrics Server
如果你对 Linux 系统有所了解的话,也许知道有一个命令 top 能够实时显示当前系统的 CPU 和内存利用率,它是性能分析和调优的基本工具,非常有用。Kubernetes 也提供了类似的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。
Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具,它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用 1m 的 CPU 和 2MB 的内存,所以性价比非常高。
下面的这张图来自 Kubernetes 官网,你可以对 Metrics Server的工作方式有个大概了解:它调用 kubelet 的 API 拿到节点和 Pod 的指标,再把这些信息交给 apiserver,这样 kubectl、HPA 就可以利用 apiserver 来读取指标了:
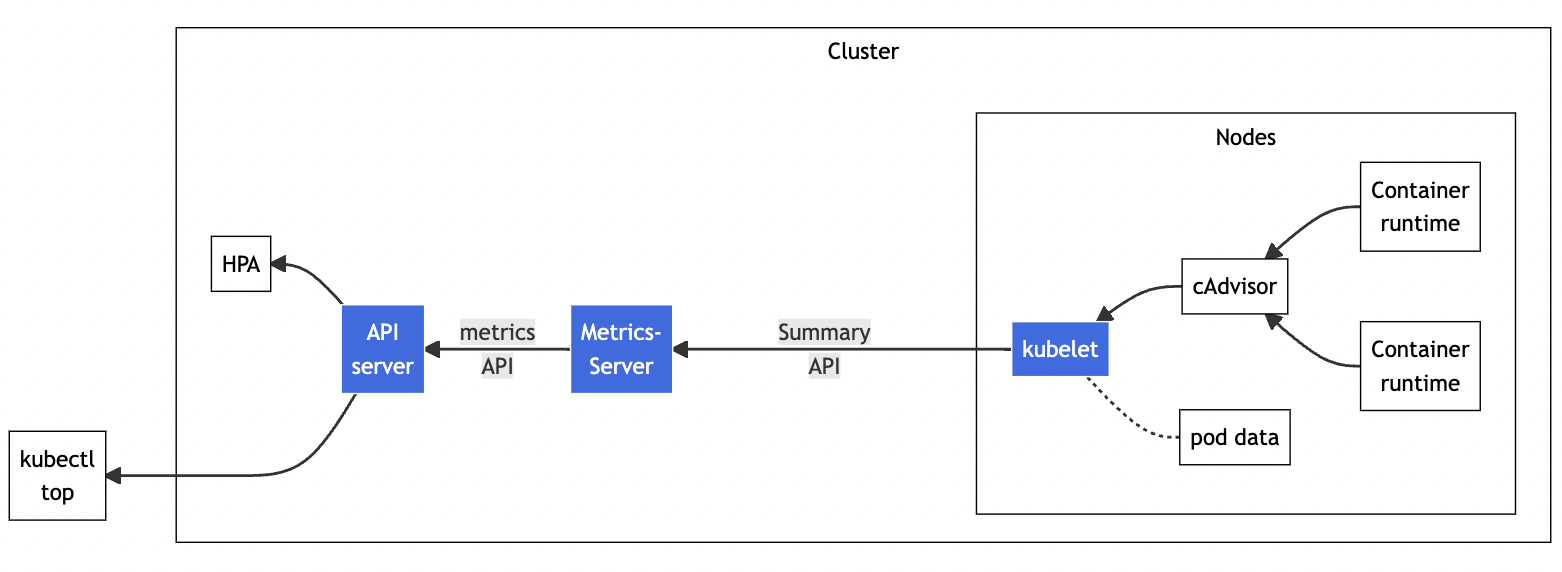
在Metrics Server 的项目网址( https://github.com/kubernetes-sigs/metrics-server)可以看到它的说明文档和安装步骤,不过如果你已经用 kubeadm 搭建了 Kubernetes 集群,就已经具备了全部前提条件,接下来只需要几个简单的操作就可以完成安装。
Metrics Server 的所有依赖都放在了一个 YAML 描述文件里,你可以使用 wget 或者 curl 下载:
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
但是在kubectl apply 创建对象之前,我们还有两个准备工作要做。
第一个工作,是修改 YAML 文件。你需要在 Metrics Server 的 Deployment 对象里,加上一个额外的运行参数 --kubelet-insecure-tls ,也就是这样:
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
spec:
... ...
template:
spec:
containers:
- args:
- --kubelet-insecure-tls
... ...
这是因为 Metrics Server 默认使用 TLS 协议,要验证证书才能与 kubelet 实现安全通信,而我们的实验环境里没有这个必要,加上这个参数可以让我们的部署工作简单很多(生产环境里就要慎用)。
第二个工作,是预先下载 Metrics Server 的镜像。看这个 YAML 文件,你会发现 Metrics Server 的镜像仓库用的是 gcr.io下载很困难。好在它也有国内的镜像网站,下载后再改名,然后把镜像加载到集群里的节点上。
给出一段 Shell 脚本代码,供你参考:
repo=registry.aliyuncs.com/google_containers
name=registry.k8s.io/metrics-server/metrics-server:v0.6.3
src_name=metrics-server:v0.6.3
docker pull $repo/$src_name
docker tag $repo/$src_name $name
docker rmi $repo/$src_name
两个准备工作都完成之后,我们就可以使用 YAML 部署 Metrics Server 了:
kubectl apply -f components.yaml
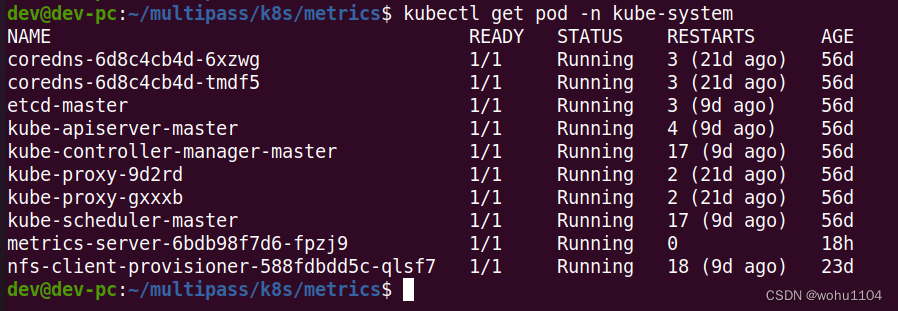
Metrics Server 属于名字空间 kube-system,可以用 kubectl get pod 加上 -n 参数查看它是否正常运行:
现在有了 Metrics Server 插件,我们就可以使用命令 kubectl top 来查看 Kubernetes 集群当前的资源状态了。它有两个子命令,node 查看节点的资源使用率,pod 查看 Pod 的资源使用率。
由于Metrics Server 收集信息需要时间,我们必须等一小会儿才能执行命令,查看集群里节点和 Pod 状态:
kubectl top node
kubectl top pod -n kube-system
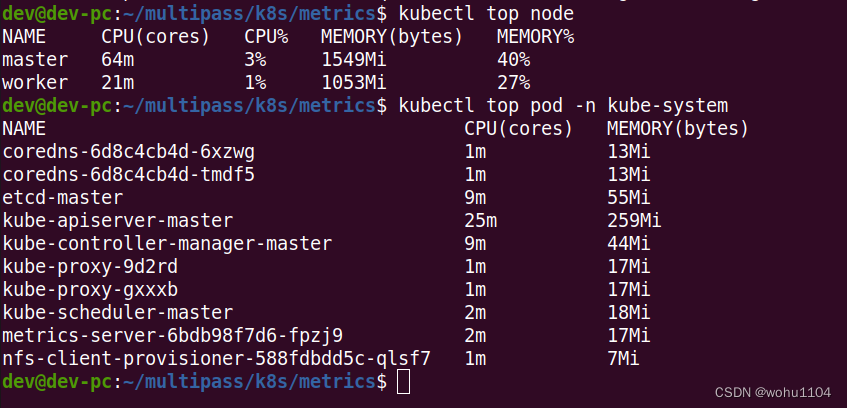
从这个截图里你可以看到:
- 集群里两个节点 CPU 使用率都不高,分别是 3% 和 1%,但内存用的很多,master 节点用了差不多一半(40%),而 worker 节点用满(27%)。
- 名字空间 kube-system里有很多 Pod,其中 apiserver 最消耗资源,使用了 25m 的 CPU 和 259MB 的内存。
2. HorizontalPodAutoscaler
有了Metrics Server,我们就可以轻松地查看集群的资源使用状况了,不过它另外一个更重要的功能是辅助实现应用的“水平自动伸缩”。
之前我们提到有一个命令 kubectl scale,可以任意增减 Deployment 部署的 Pod 数量,也就是水平方向的“扩容”和“缩容”。但是手动调整应用实例数量还是比较麻烦的,需要人工参与,也很难准确把握时机,难以及时应对生产环境中突发的大流量,所以最好能把这个“扩容”“缩容”也变成自动化的操作。
Kubernetes 为此就定义了一个新的 API 对象,叫做 HorizontalPodAutoscaler,简称是 hpa。顾名思义,它是专门用来自动伸缩 Pod 数量的对象,适用于 Deployment 和 StatefulSet,但不能用于 DaemonSet(原因很明显吧)。
HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量。
下面我们就来看看该怎么使用 HorizontalPodAutoscaler,首先要定义 Deployment 和 Service,创建一个 Nginx 应用,作为自动伸缩的目标对象:
# ngx-hpa-dep.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-hpa-dep
spec:
replicas: 1
selector:
matchLabels:
app: ngx-hpa-dep
template:
metadata:
labels:
app: ngx-hpa-dep
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: ngx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: ngx-hpa-dep
在这个YAML 里只部署了一个 Nginx 实例,名字是 ngx-hpa-dep。
注意在它的
spec里一定要用resources字段写清楚资源配额,否则HorizontalPodAutoscaler会无法获取Pod的指标,也就无法实现自动化扩缩容。
kubectl apply -f ngx-hpa-dep.yml
接下来我们要用命令 kubectl autoscale 创建一个 HorizontalPodAutoscaler 的样板 YAML 文件,它有三个参数:
- min:Pod 数量的最小值,也就是缩容的下限。
- max:Pod 数量的最大值,也就是扩容的上限。
- cpu-percent:CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容。
好,现在我们就来为刚才的 Nginx 应用创建 HorizontalPodAutoscaler,指定 Pod 数量最少 2 个,最多 10 个,CPU 使用率指标设置的小一点,5%,方便我们观察扩容现象:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl autoscale deploy ngx-hpa-dep --min=2 --max=10 --cpu-percent=5 $out
得到的YAML 描述文件就是这样:
# ngx-hpa.yml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ngx-hpa
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ngx-hpa-dep
targetCPUUtilizationPercentage: 5
我们再使用命令 kubectl apply 创建这个 HorizontalPodAutoscaler 后,它会发现 Deployment 里的实例只有 1 个,不符合 min 定义的下限的要求,就先扩容到 2 个:
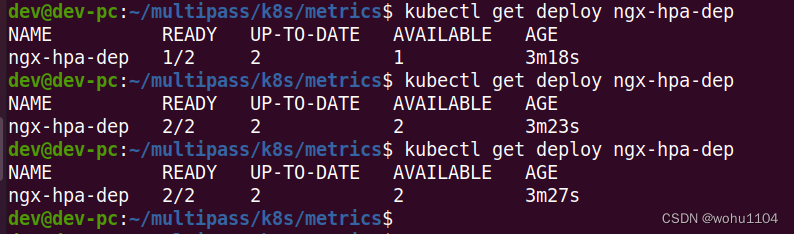

从这张截图里你可以看到,HorizontalPodAutoscaler 会根据 YAML 里的描述,找到要管理的 Deployment,把 Pod 数量调整成 2 个,再通过 Metrics Server 不断地监测 Pod 的 CPU 使用率。
下面我们来给 Nginx 加上压力流量,运行一个测试 Pod,使用的镜像是“httpd:alpine”,它里面有 HTTP 性能测试工具 ab(Apache Bench):
kubectl run test -it --image=httpd:alpine -- sh
然后我们向 Nginx 发送一百万个请求,持续 1 分钟,再用 kubectl get hpa 来观察 HorizontalPodAutoscaler 的运行状况:
ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
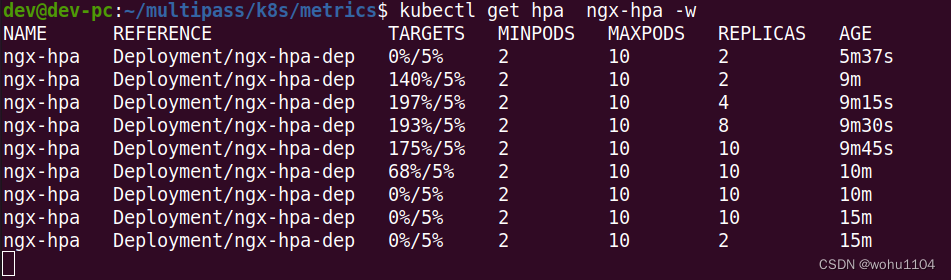
因为Metrics Server 大约每 15 秒采集一次数据,所以 HorizontalPodAutoscaler 的自动化扩容和缩容也是按照这个时间点来逐步处理的。
当它发现目标的 CPU 使用率超过了预定的 5% 后,就会以 2 的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果 CPU 使用率回落,就会再缩容到最小值。
3. Prometheus
显然,有了 Metrics Server 和 HorizontalPodAutoscaler 的帮助,我们的应用管理工作又轻松了一些。不过,Metrics Server 能够获取的指标还是太少了,只有 CPU 和内存,想要监控到更多更全面的应用运行状况,还得请出这方面的权威项目 Prometheus。
下面的这张图是 Prometheus 官方的架构图,
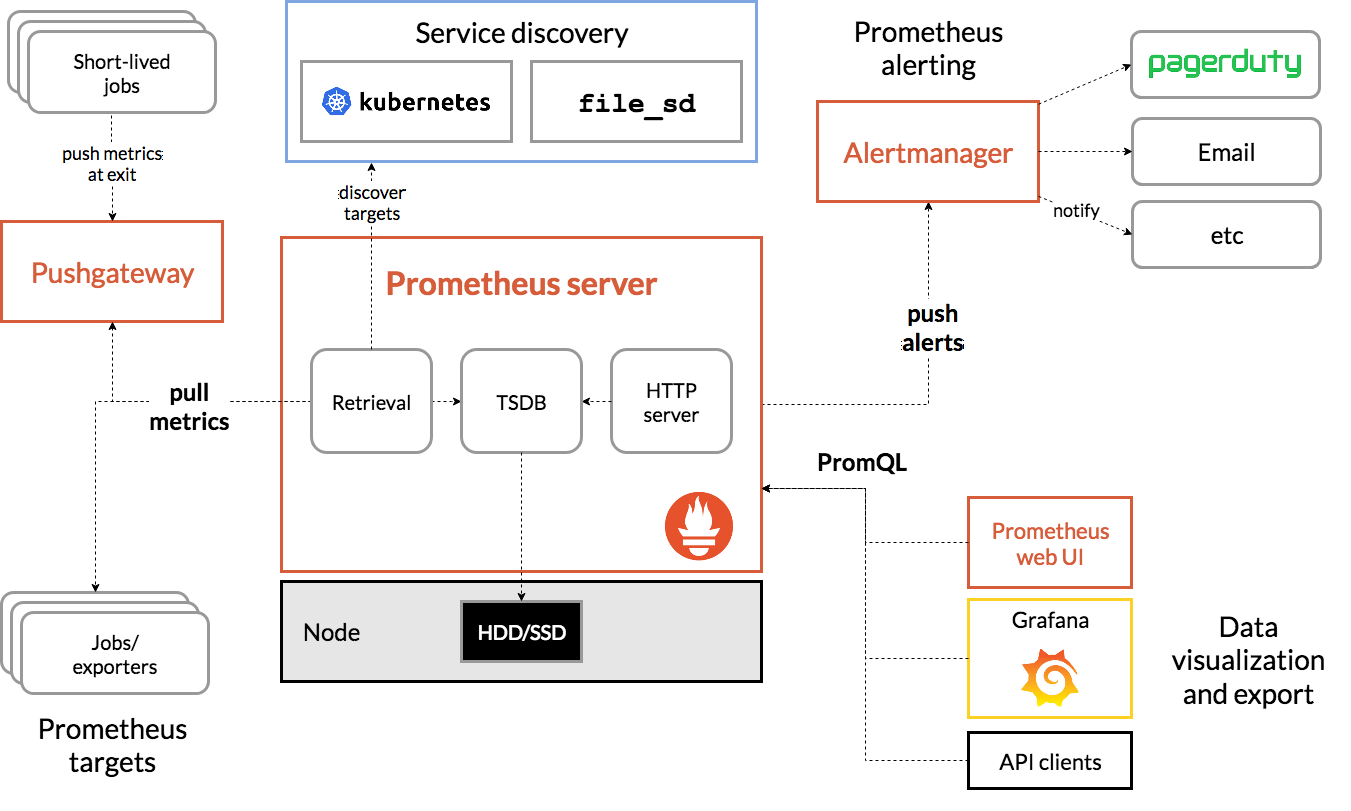
Prometheus 系统的核心是它的 Server,里面有一个时序数据库 TSDB,用来存储监控数据,另一个组件 Retrieval 使用拉取(Pull)的方式从各个目标收集数据,再通过 HTTP Server 把这些数据交给外界使用。
在Prometheus Server 之外还有三个重要的组件:
- Push Gateway,用来适配一些特殊的监控目标,把默认的 Pull 模式转变为 Push 模式。
- Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
- Grafana 是图形化界面,可以定制大量直观的监控仪表盘。
由于同属于 CNCF,所以 Prometheus 自然就是“云原生”,在 Kubernetes 里运行是顺理成章的事情。不过它包含的组件实在是太多,部署起来有点麻烦,这里我选用了 kube-prometheus项目(https://github.com/prometheus-operator/kube-prometheus/),感觉操作起来比较容易些。
我们先要下载 kube-prometheus 的源码包,当前的最新版本是 0.11:
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.11.0.tar.gz
解压缩后,Prometheus 部署相关的 YAML 文件都在 manifests 目录里,有近 100 个,你可以先大概看一下。
和Metrics Server 一样,我们也必须要做一些准备工作,才能够安装 Prometheus。
第一步,是修改 prometheus-service.yaml、grafana-service.yaml。
这两个文件定义了 Prometheus 和 Grafana 服务对象,我们可以给它们添加 type: NodePort(参考第 20 讲),这样就可以直接通过节点的 IP 地址访问(当然你也可以配置成 Ingress)。
第二步,是修改 kubeStateMetrics-deployment.yaml、prometheusAdapter-deployment.yaml,因为它们里面有两个存放在 gcr.io 的镜像,必须解决下载镜像的问题。
但很遗憾,我没有在国内网站上找到它们的下载方式,为了能够顺利安装,只能把它们下载后再上传到 Docker Hub 上。所以你需要修改镜像名字,把前缀都改成 chronolaw:
image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
image: chronolaw/kube-state-metrics:v2.5.0
image: chronolaw/prometheus-adapter:v0.9.1
这两个准备工作完成之后,我们要执行两个 kubectl create 命令来部署 Prometheus,先是 manifests/setup 目录,创建名字空间等基本对象,然后才是 manifests 目录:
kubectl create -f manifests/setup
kubectl create -f manifests
Prometheus 的对象都在名字空间 monitoring里,创建之后可以用 kubectl get 来查看状态:
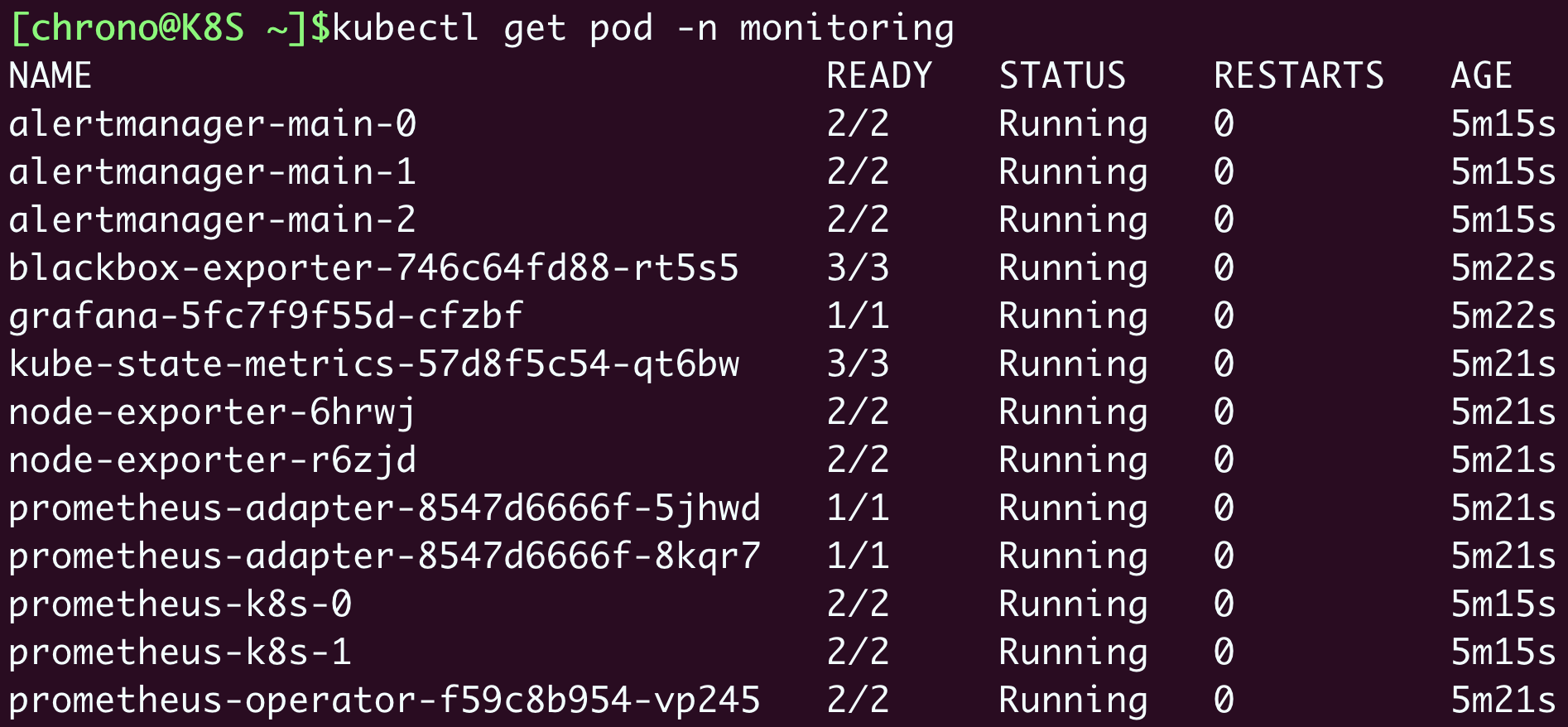
确定这些 Pod 都运行正常,我们再来看看它对外的服务端口:
kubectl get svc -n monitoring
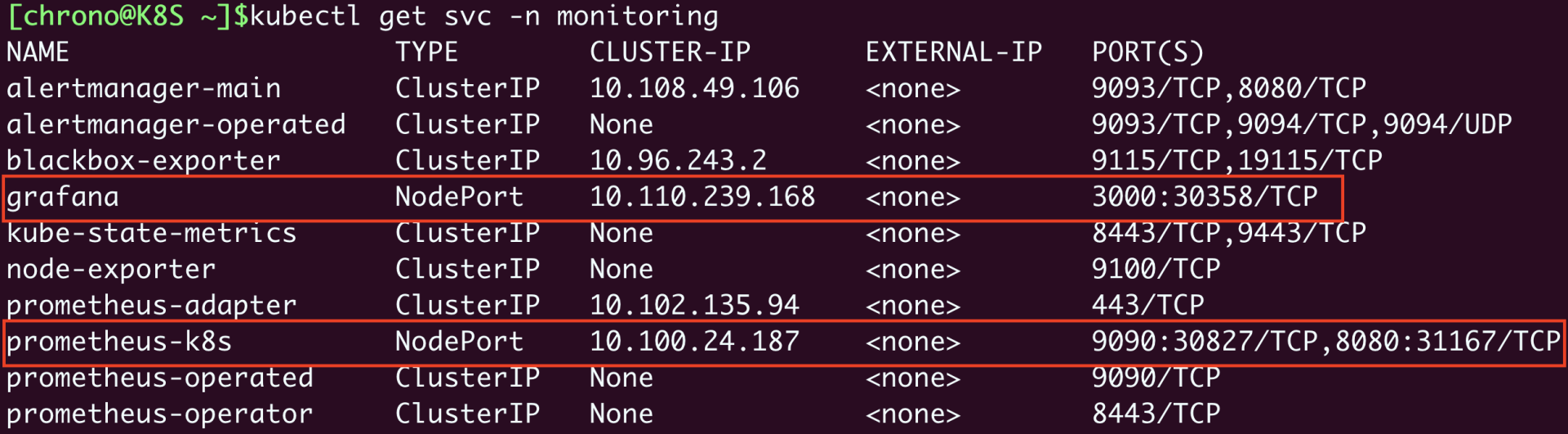
前面修改了 Grafana 和 Prometheus 的 Service 对象,所以这两个服务就在节点上开了端口,Grafana 是“30358”,Prometheus 有两个端口,其中“9090”对应的“30827”是 Web 端口。
在浏览器里输入节点的 IP 地址(我这里是“http://192.168.10.210”),再加上端口号“30827”,我们就能看到 Prometheus 自带的 Web 界面,:
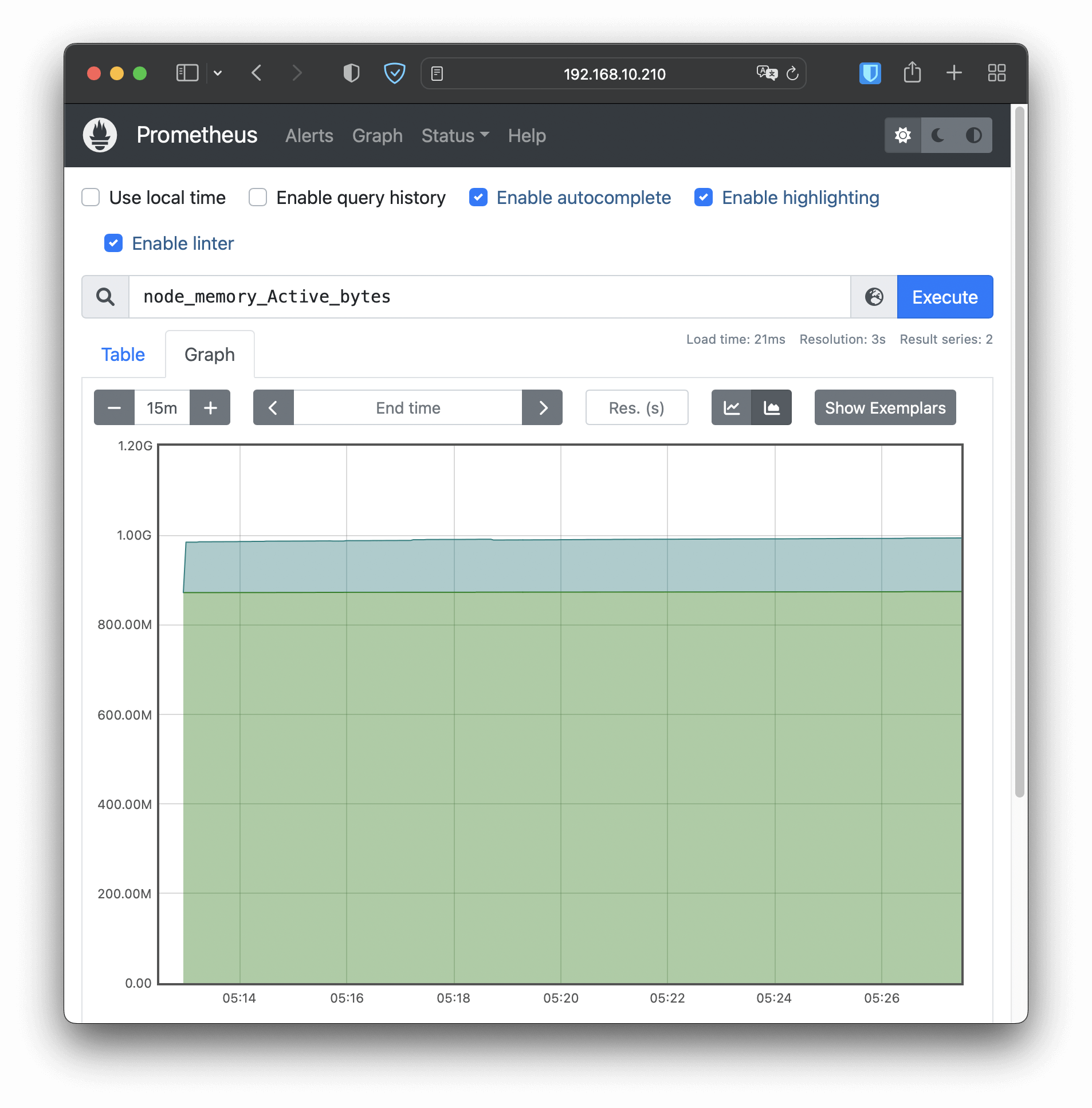
Web界面上有一个查询框,可以使用 PromQL 来查询指标,生成可视化图表,比如在这个截图里我就选择了“node_memory_Active_bytes”这个指标,意思是当前正在使用的内存容量。
Prometheus 的 Web 界面比较简单,通常只用来调试、测试,不适合实际监控。我们再来看 Grafana,访问节点的端口“30358”(我这里是“http://192.168.10.210:30358”),它会要求你先登录,默认的用户名和密码都是“admin”:
 Grafana 内部已经预置了很多强大易用的仪表盘,你可以在左侧菜单栏的“Dashboards - Browse”里任意挑选一个:
Grafana 内部已经预置了很多强大易用的仪表盘,你可以在左侧菜单栏的“Dashboards - Browse”里任意挑选一个:
比如我选择了“Kubernetes / Compute Resources / Namespace (Pods)”这个仪表盘,就会出来一个非常漂亮图表,比 Metrics Server 的 kubectl top 命令要好看得多,各种数据一目了然:
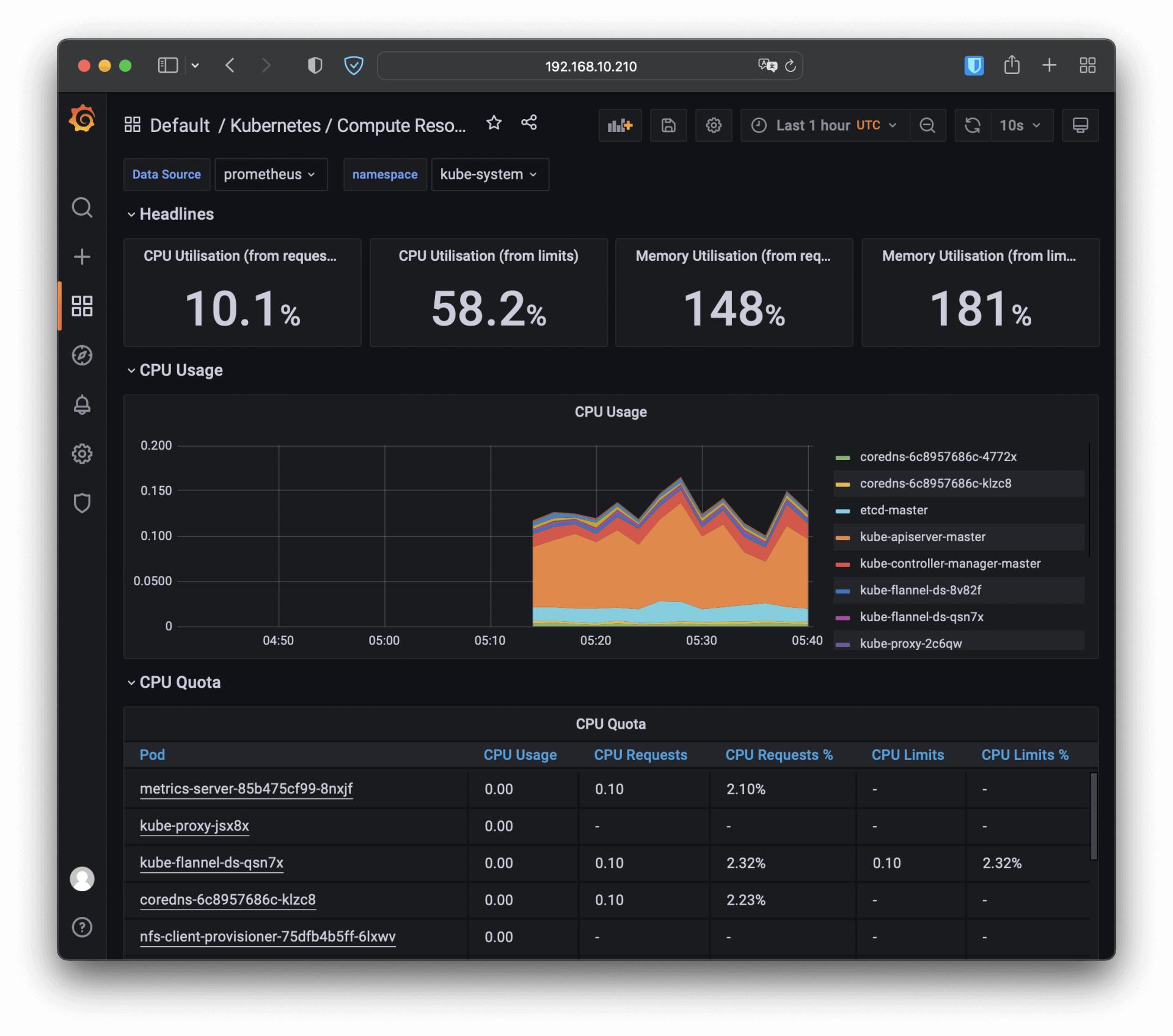
4. 总结
1、 MetricsServer是一个Kubernetes插件,能够收集系统的核心资源指标,相关的命令是kubectltop;
2、 Prometheus是云原生监控领域的“事实标准”,用PromQL语言来查询数据,配合Grafana可以展示直观的图形界面,方便监控;
3、 HorizontalPodAutoscaler实现了应用的自动水平伸缩功能,它从MetricsServer获取应用的运行指标,再实时调整Pod数量,可以很好地应对突发流量;
Metrics Server 早期的数据来源是 cAdvisor,它是一个独立的应用程序,后来被精简集成进了 kubelet。
当前的HorizontalPodAutoscaler 版本是 v2,除了支持 CPU 指标外也支持自定义指标,还有更多的可调节参数,但命令 kubectl autoscale 创建的样板 yaml 默认用的是 v1。
通常来说运行 Grafana 要预先定于数据源,指定 Prometheus 地址,但 kube-prometheus 已经把这些都配置好了,我们可以直接开箱即用。
Grafana 官网上有很多定义好的仪表盘,是一个类似 GitHub、DockerHub 的社区,可以任意下载,只需要输入数字编号就可以把仪表盘导入到本地。