一、消息生产
1 消息的生产过程
Producer可以将消息写入到某Broker中的某Queue中,其经历了如下过程:
- Producer发送消息之前,会先向NameServer发出获取消息Topic的路由信息的请求
- NameServer返回该Topic的路由表及Broker列表
- Producer根据代码中指定的Queue选择策略,从Queue列表中选出一个队列,用于后续存储消息
- Produer对消息做一些特殊处理,例如,消息本身超过4M,则会对其进行压缩
- Producer向选择出的Queue所在的Broker发出RPC请求,将消息发送到选择出的Queue
路由表:实际是一个Map,key为Topic名称,value是一个QueueData实例列表。QueueData并不是一个Queue对应一个QueueData,而是一个Broker中该Topic的所有Queue对应一个
QueueData。
即,只要涉及到该Topic的Broker,一个Broker对应一个QueueData。QueueData中包含brokerName。
简单来说,路由表的key为Topic名称,value则为所有涉及该Topic的BrokerName列表。
Broker列表:其实际也是一个Map。key为brokerName,value为BrokerData。
一个Broker对应一 个BrokerData实例,对吗?
不对。
一套brokerName名称相同的Master-Slave小集群对应一个BrokerData。
BrokerData中包含brokerName及一个map。
该map的key为brokerId,value为该broker对应的地址。
brokerId为0表示该broker为Master,非0表示Slave。
2 Queue选择算法
对于无序消息,其Queue选择算法,也称为消息投递算法,常见的有两种:
轮询算法
默认选择算法。该算法保证了每个Queue中可以均匀的获取到消息。
该算法存在一个问题:由于某些原因,在某些Broker上的Queue可能投递延迟较严重。从而导致Producer的缓存队列中出现较大的消息积压,影响消息的投递性能。
最小投递延迟算法
该算法会统计每次消息投递的时间延迟,然后根据统计出的结果将消息投递到时间延迟最小的Queue。
如果延迟相同,则采用轮询算法投递。该算法可以有效提升消息的投递性能。
该算法也存在一个问题:消息在Queue上的分配不均匀。投递延迟小的Queue其可能会存在大量的消息。而对该Queue的消费者压力会增大,降低消息的消费能力,可能会导致MQ中消息的堆积。
二、消息存储
RocketMQ中的消息存储在本地文件系统中,这些相关文件默认在当前用户主目录下的store目录中。
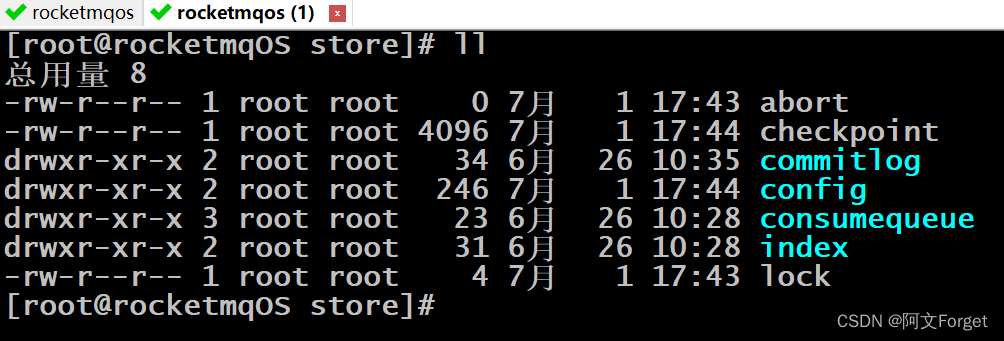
- abort:该文件在Broker启动后会自动创建,正常关闭Broker,该文件会自动消失。若在没有启动Broker的情况下,发现这个文件是存在的,则说明之前Broker的关闭是非正常关闭。
- checkpoint:其中存储着commitlog、consumequeue、index文件的最后刷盘时间戳
- commitlog:其中存放着commitlog文件,而消息是写在commitlog文件中的
- config:存放着Broker运行期间的一些配置数据
- consumequeue:其中存放着consumequeue文件,队列就存放在这个目录中
- index:其中存放着消息索引文件indexFile
- lock:运行期间使用到的全局资源锁
1 commitlog文件
说明:在很多资料中commitlog目录中的文件简单就称为commitlog文件。但在源码中,该文件被命名为mappedFile。
目录与文件
commitlog目录中存放着很多的mappedFile文件,当前Broker中的所有消息都是落盘到这些mappedFile文件中的。
mappedFile文件大小为1G(小于等于1G),文件名由20位十进制数构成,表示当前文件的第一条消息的起始位移偏移量。
第一个文件名一定是20位0构成的。因为第一个文件的第一条消息的偏移量commitlog offset为0
当第一个文件放满时,则会自动生成第二个文件继续存放消息。假设第一个文件大小是1073741820字节(1G = 1073741824字节),则第二个文件名就是00000000001073741824。
以此类推,第n个文件名应该是前n-1个文件大小之和。
一个Broker中所有mappedFile文件的commitlog offset是连续的
需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中的。
即无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中的。
也就是说,这些消息在Broker中存放时并没有被按照Topic进行分类存放。
mappedFile文件是顺序读写的文件,所有其访问效率很高
无论是SSD磁盘还是SATA磁盘,通常情况下,顺序存取效率都会高于随机存取。
消息单元
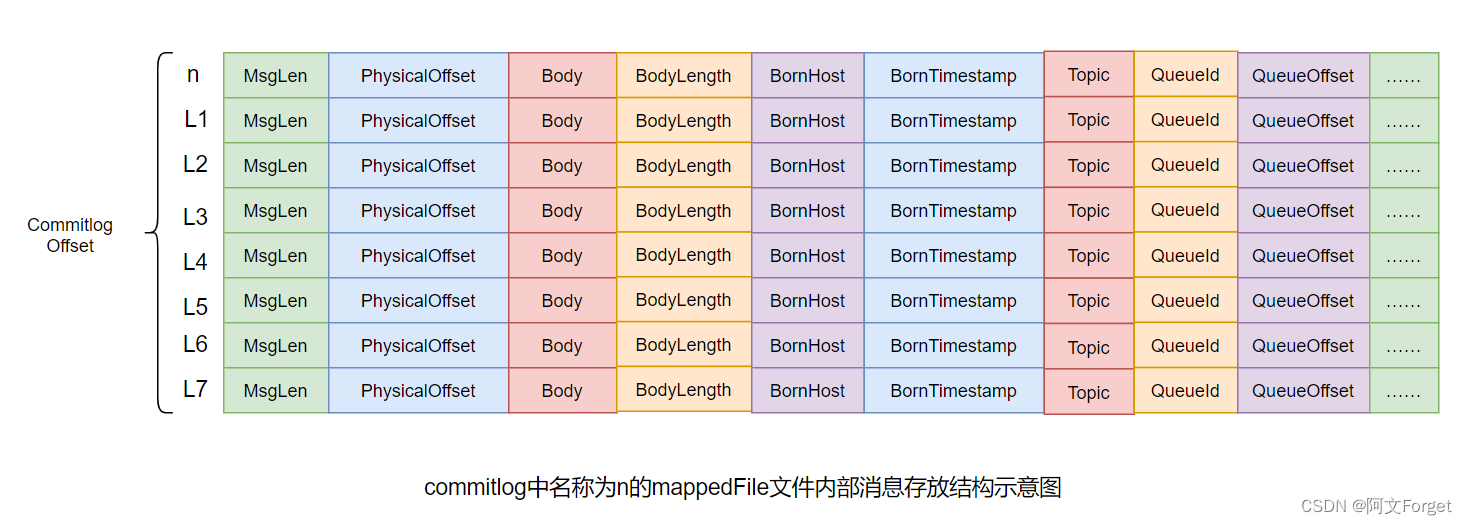
mappedFile文件内容由一个个的消息单元构成。每个消息单元中包含消息总长度MsgLen、消息的物理位置physicalOffset、消息体内容Body、消息体长度BodyLength、消息主题Topic、Topic长度
TopicLength、消息生产者BornHost、消息发送时间戳BornTimestamp、消息所在的队列QueueId、消息在Queue中存储的偏移量QueueOffset等近20余项消息相关属性。
需要注意到,消息单元中是包含Queue相关属性的。所以,我们在后续的学习中,就需要十分留意commitlog与queue间的关系是什么?
一个mappedFile文件中第m+1个消息单元的commitlog offset偏移量
L(m+1) = L(m) + MsgLen(m) (m >= 0)
2 consumequeue
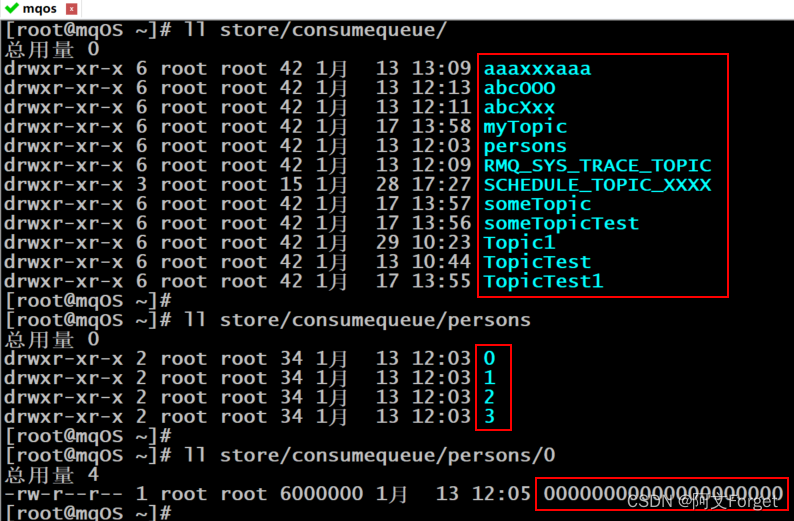
目录与文件
为了提高效率,会为每个Topic在~/store/consumequeue中创建一个目录,目录名为Topic名称。在该Topic目录下,会再为每个该Topic的Queue建立一个目录,目录名为queueId。
每个目录中存放着若干consumequeue文件,consumequeue文件是commitlog的索引文件,可以根据consumequeue定位到具体的消息。
consumequeue文件名也由20位数字构成,表示当前文件的第一个索引条目的起始位移偏移量。与mappedFile文件名不同的是,其后续文件名是固定的。因为consumequeue文件大小是固定不变的。
索引条目
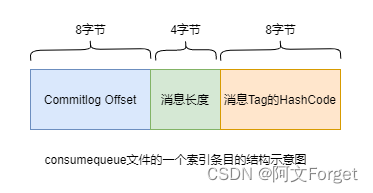
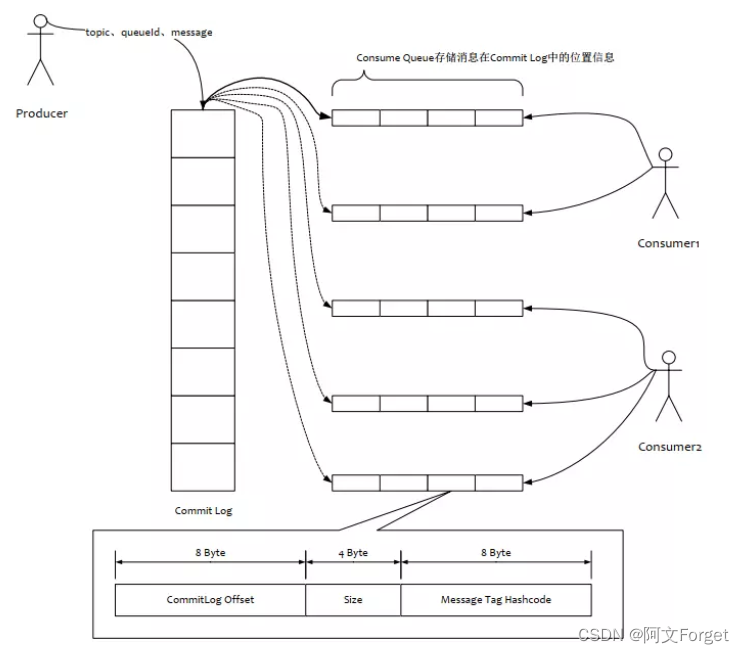
每个consumequeue文件可以包含30w个索引条目,每个索引条目包含了三个消息重要属性:
消息在mappedFile文件中的偏移量CommitLog Offset、消息长度、消息Tag的hashcode值。
这三个属性占20个字节,所以每个文件的大小是固定的30w * 20字节。
一个consumequeue文件中所有消息的Topic一定是相同的。但每条消息的Tag可能是不同的。
3 对文件的读写
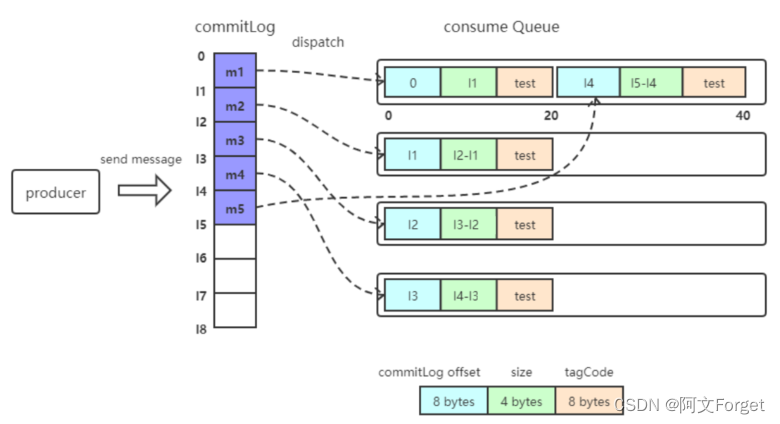
消息写入
一条消息进入到Broker后经历了以下几个过程才最终被持久化。
- Broker根据queueId,获取到该消息对应索引条目要在consumequeue目录中的写入偏移量,即QueueOffset
- 将queueId、queueOffset等数据,与消息一起封装为消息单元
- 将消息单元写入到commitlog
- 同时,形成消息索引条目
- 将消息索引条目分发到相应的consumequeue
消息拉取
当Consumer来拉取消息时会经历以下几个步骤:
- Consumer获取到其要消费消息所在Queue的消费偏移量offset ,计算出其要消费消息的消息offset
消费offset即消费进度,consumer对某个Queue的消费offset,即消费到了该Queue的第几条消息
消息offset = 消费offset + 1
- Consumer向Broker发送拉取请求,其中会包含其要拉取消息的Queue、消息offset及消息Tag。
- Broker计算在该consumequeue中的queueOffset。
queueOffset = 消息offset * 20字节
- 从该queueOffset处开始向后查找第一个指定Tag的索引条目。
- 解析该索引条目的前8个字节,即可定位到该消息在commitlog中的commitlog offset
- 从对应commitlog offset中读取消息单元,并发送给Consumer
性能提升
RocketMQ中,无论是消息本身还是消息索引,都是存储在磁盘上的。其不会影响消息的消费吗?
当然不会。其实RocketMQ的性能在目前的MQ产品中性能是非常高的。因为系统通过一系列相关机制大大提升了性能。
首先,RocketMQ对文件的读写操作是通过mmap零拷贝进行的,将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率。
其次,consumequeue中的数据是顺序存放的,还引入了PageCache的预读取机制,使得对consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能。
PageCache机制,页缓存机制,是OS对文件的缓存机制,用于加速对文件的读写操作。
一般来说,程序对文件进行顺序读写的速度几乎接近于内存读写速度,主要原因是由于OS使用PageCache机制对读写访问操作进行性能优化,将一部分的内存用作PageCache。
- 写操作:OS会先将数据写入到PageCache中,随后会以异步方式由push(page dirty push)
内核线程将Cache中的数据刷盘到物理磁盘 - 读操作:若用户要读取数据,其首先会从PageCache中读取,若没有命中,则OS在从物理磁盘上加载该数据到PageCache的同时,也会顺序对其相邻数据块中的数据进行预读取。
RocketMQ中可能会影响性能的是对commitlog文件的读取。因为对commitlog文件来说,读取消息时会产生大量的随机访问,而随机访问会严重影响性能。
不过,如果选择合适的系统IO调度算法,比如
设置调度算法为Deadline(采用SSD固态硬盘的话),随机读的性能也会有所提升。
4 与Kafka的对比
RocketMQ的很多思想来源于Kafka,其中commitlog与consumequeue就是。
RocketMQ中的commitlog目录与consumequeue的结合就类似于Kafka中的partition分区目录。
mappedFile文件就类似于Kafka中的segment段。
Kafka中的Topic的消息被分割为一个或多个partition。partition是一个物理概念,对应到系统上
就是topic目录下的一个或多个目录。每个partition中包含的文件称为segment,是具体存放消息的文件。
Kafka中消息存放的目录结构是:topic目录下有partition目录,partition目录下有segment文件
Kafka中没有二级分类标签Tag这个概念
Kafka中无需索引文件。因为生产者是将消息直接写在了partition中的,消费者也是直接从partition中读取数据的
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: